
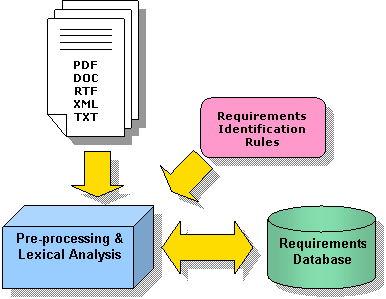
Key Features :
1. Automatically processes Microsoft® Word (doc, rtf, xml), Adobe® Acrobat (pdf, ps) and plain text files (txt).
2. Identification of requirements according to configurable rules (requirement number, presence of keywords, etc.).
3. Extracts textual elements from the document
into single sentence requirements.
4. Generation of XML format requirements loaded into
a database for lexical analysis.
5. Each requirement is parsed using Natural Language
Processing Techniques to extract the part-of-speech
language tags.

